问题分诊室
听得见,更“慧”听:揭秘AI+声学的无限可能
发布时间: 2026-04-01
人工智能(AI),正与声学中的水声学、超声学和空气声学深度交叉融合,持续推动着声学技术的革新。《科技导报》邀请中国科学院大学郑成诗研究员团队撰写文章,重点探讨了AI在声学,尤其是在空气声学领域中的应用。针对应用过程中可能出现并致使其难以满足实际应用需求的核心问题展开讨论。最后,总结了AI在声学应用中所面临的挑战和未来的发展方向。
声学作为物理学的一个重要分支,按照声波传播媒介分为水声学、超声学和空气声学,分别研究声波在液体中(水中)、固体中和空气中的科学问题与实践应用。相较于声学的悠久历史,AI则是始于20世纪40年代的新兴交叉学科,已与计算机科学、数学、神经科学等领域深度融合。近年来,以深度学习( DL)为核心技术路线的NAI已经在视觉和听觉等领域接连取得突破,甚至部分任务(如中英文语音识别)性能已超越人类水平。随着DL的飞速发展,能够在众多领域模拟人类处理问题的通用人工智能(AGI)应运而生,成为科技巨头竞争的焦点,同时也已成为大国综合国力竞争的制高点。
AI与声学的结合始于20世纪50年代,早期主要应用于语音识别和语音合成领域,典型代表为贝尔实验室在1952年开发的首个人工语音识别系统“Audrey”。经过70余年的融合发展,其在声学领域的应用已超越语音信号处理范畴,深度融入语音处理、声源定位、空间音频、声学场景检测与分类及声学仿真与优化等多个分支领域,全面推动水声学、超声学和空气声学的技术革新,显著提升各分支领域的性能表现。
我们的研究聚焦AI在声学中的应用,重点阐述“AI+声学”技术的发展现状,并与传统声学技术展开对比分析,剖析该领域所面临的多重挑战,并对“AI+声学”技术的未来发展方向进行展望。
1、基本概念
1.1 声学基本概念
声学主要研究声音的产生、传播、接收和效应等。不同类型的声音通常在频率、声压级、频谱等物理属性上存在差异,在心理属性上则对应于音调、响度和音色的差异。
对在空间中传播的声音进行接收、处理、识别和定位及调控是当前声学的研究热点。对语音进行捡拾、定位、增强、识别和合成,已成为声学领域最为重要的研究分支之一;对其他类型的声音信号进行有效捡拾、处理、检测和定位,也得到了广泛的关注和研究。
1.2 AI基本技术
AI技术源于对人类智能的模拟与探索,其早期演进为现代核心模型架构奠定了重要基础。经过数十年演进,AI领域形成了以经典模型为核心的技术体系,各模型凭借独特结构适配不同数据处理需求,如图1所示。
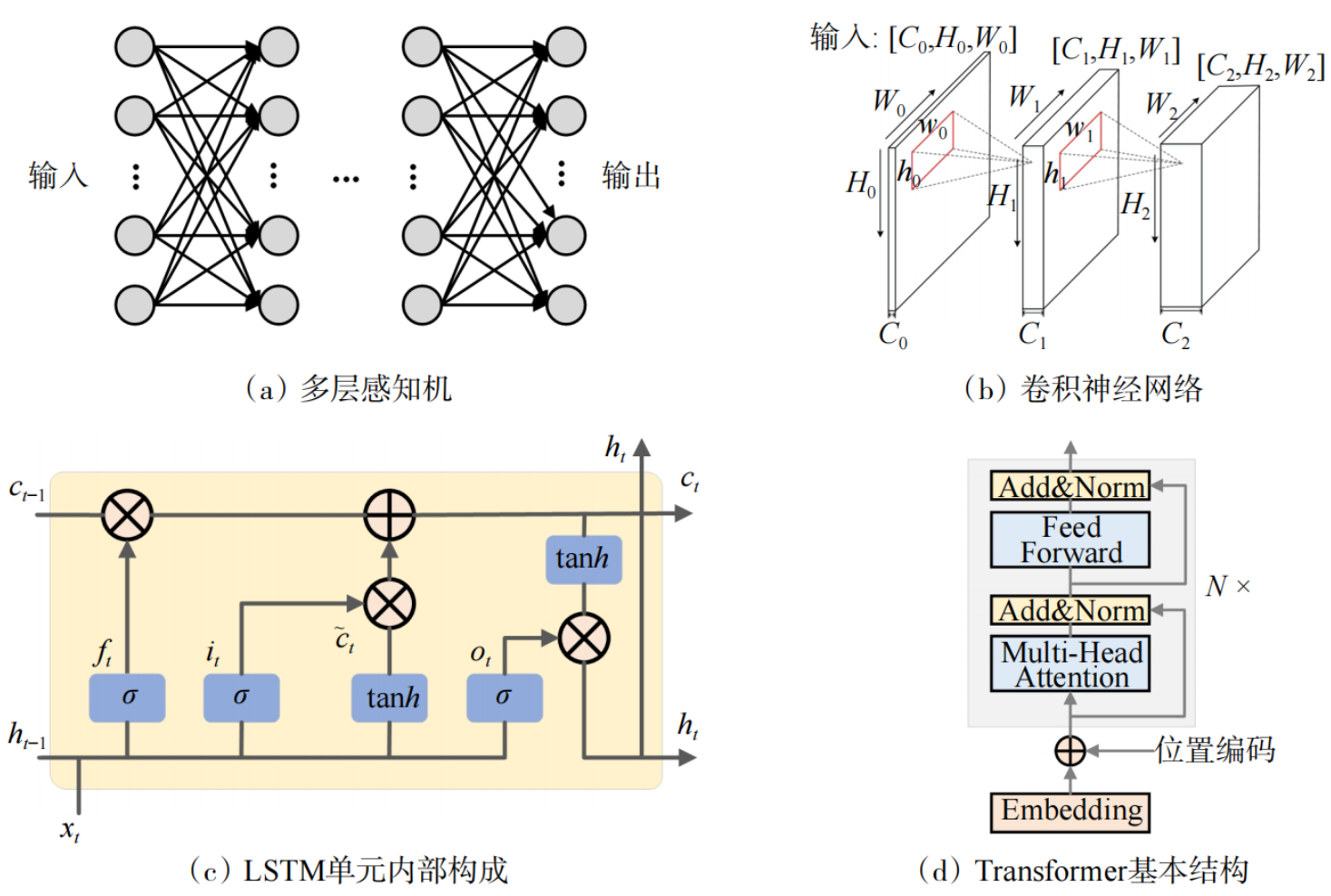
图1 不同AI基本模型结构示意
卷积神经网络(CNN)以“局部感知+参数共享”为核心,通过卷积核捕获数据局部关联特征,在减少参数量的同时保留关键信息。其结构在局部相关性数据处理中表现突出,可高效提取层级化特征,适配多通道信号、图像等数据类型。
长短期记忆网络(LSTM)是适配时序数据的循环神经网络(RNN)变体,通过遗忘门、输入门、输出门的门控机制,解决传统RNN面临的长序列梯度消失(gradient vanishing)问题。
Transformer模型于2017年由Google提出,核心为自注意力(SA)机制,通过计算数据不同位置间的关联权重,实现全局信息的并行捕获与动态聚焦。相较于LSTM的时序渐进式处理,其可同步整合全局上下文信息,强化关键信息的特征表达,在长时长、高冗余的复杂数据处理中优势显著。
这些核心技术从早期简单模型逐步演进为复杂高效的架构体系,为不同类型数据的解析提供了针对性工具,与声学概念互补,共同支撑起了“AI+声学”的融合应用与创新发展。
2、应用现状
从技术应用现状来看,传统声学处理整体围绕5大核心需求展开,为后续细分应用场景提供基础支撑:针对语音信号的“采集−特征提取−语义解析”需求;针对声音空间位置确定的需求;针对声场空间信息还原与个性化体验需求;针对环境中有效噪声信号与分类的需求;针对声学组件性能评估与结构设计需求。
2.1 AI+语音信号处理
语音信号处理作为AI与声学交叉融合的核心领域,其发展历程见证了从统计信号模型到数据驱动范式的转变。早期的语音信号处理技术如语音识别主要基于隐马尔可夫模型(HMM)处理常用语音特征。随着AI技术的兴起,CNN凭借分层时频特征提取能力展现出显著优势,而LSTM因自回归处理模式,契合语音分帧处理模式和时间序列信号特性,被广泛应用于各类语音信号处理任务中。
2.1.1 语音识别
在语音识别领域,2012年,微软研究院与Google率先使用深度神经网络( DNN),将语音识别错误率降低20%~30%。这一突破标志着语音识别从依赖手工设计特征与传统模型,转向基于数据驱动的DNN范式。2015年,百度公司提出DeepSpeech 2,在中文语音识别任务中首次超越人类专业速记员水平。2023年,OpenAI推出了Whisper模型,实现了语音识别、转写与翻译的一体化突破,显著提升了复杂环境与低资源语种识别的鲁棒性。
随着研究深入,多模态融合的语音识别技术成为新的研究热点。在语音与视觉联合建模中,研究人员通过摄像头捕捉说话人的唇动信息,利用跨模态特征融合技术实现唇动特征与语音特征的精准对齐(图2)。近年来,脑机接口与语音识别的融合也取得了突破性进展,例如,Kamble等尝试结合脑电图(EEG)信号进行语音识别,取得了一些进展。但由于脑电信号具有高噪声、个体差异大等复杂性,该技术在性能与泛化性方面仍存在巨大的研究提升空间。
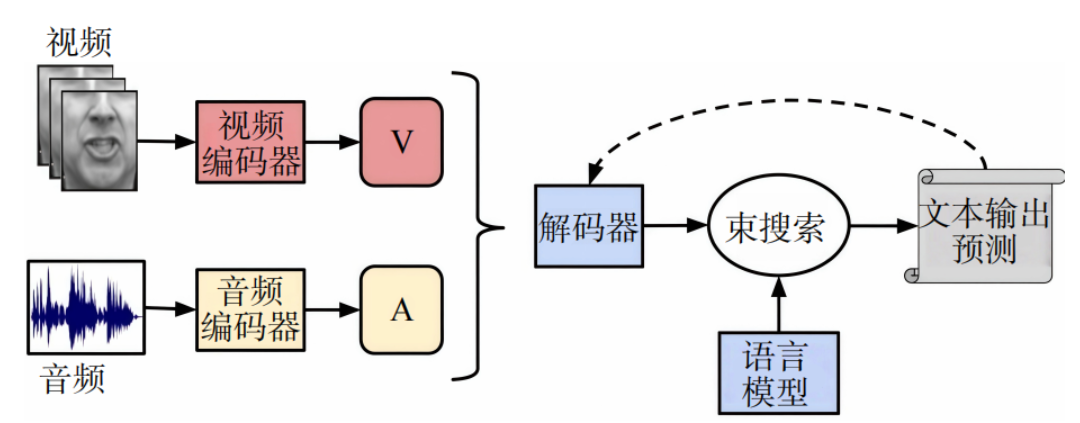
图2 唇动−语音多模态识别系统示意
2.1.2 语音增强
随着深度学习技术的发展,数据驱动的语音增强技术通过构建带噪与纯净语音的非线性映射关系,实现了从“模型假设”到“数据学习”的范式转变。2014年,Xu等利用多层DNN学习带噪语音对数谱到干净对数谱的非线性映射(图3),相比传统算法,其在各项指标上实现显著提升。近年来,一系列相关比赛也为该方向的发展注入新的活力,微软公司于2020年发起深度降噪(DNS)挑战赛,迄今已连续举办5年,该比赛的举办进一步推动了该领域进步。然而,面对实际场景中可能出现的模态缺失问题,如何提升多模态语音增强方法的鲁棒性,仍是亟待解决的关键问题。
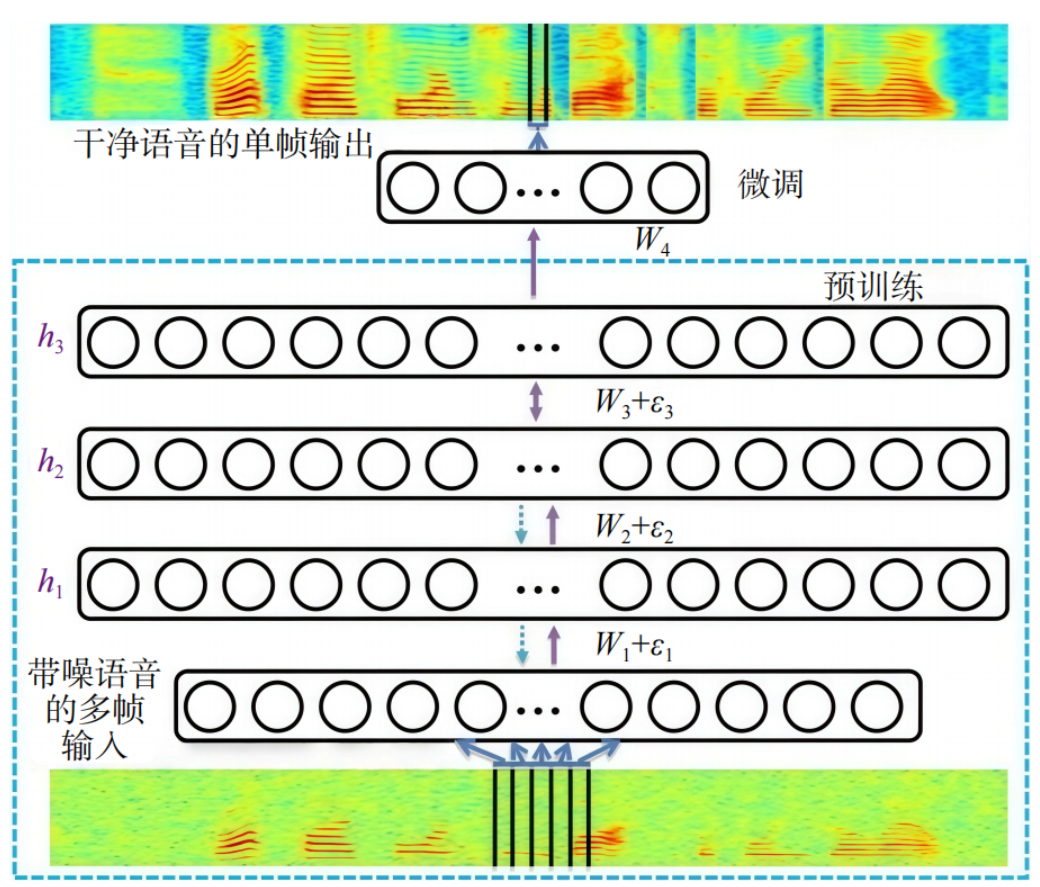
图3 基于DNN的语音增强示意
2.1.3 语音合成
语音合成技术经历了从参数化统计语音合成到端到端生成的跨越式演进。随着AI技术在生成式建模领域的突破,语音合成实现了从“参数驱动”到“数据驱动”的根本性转变。2016年,DeepMind推出的WaveNet模型取得了合成语音质量的突破性进展(图4),显著提升了合成语音的自然度,平均意见得分(MOS)从传统参数化合成方法的3.6提升至4.0以上。浙江大学研究人员提出FastSpeech系列工作,通过时长预测与声学特征解耦的设计,在保持高自然度的同时,将语音合成速度提升了数十倍。近年来,LLM和DM为语音合成带来了新的技术突破。此外,多模态融合与个性化合成已成为当前研究热点,为定制化语音生成与高表现力语音提供了可能,在娱乐、人机交互等领域具有重要应用价值。
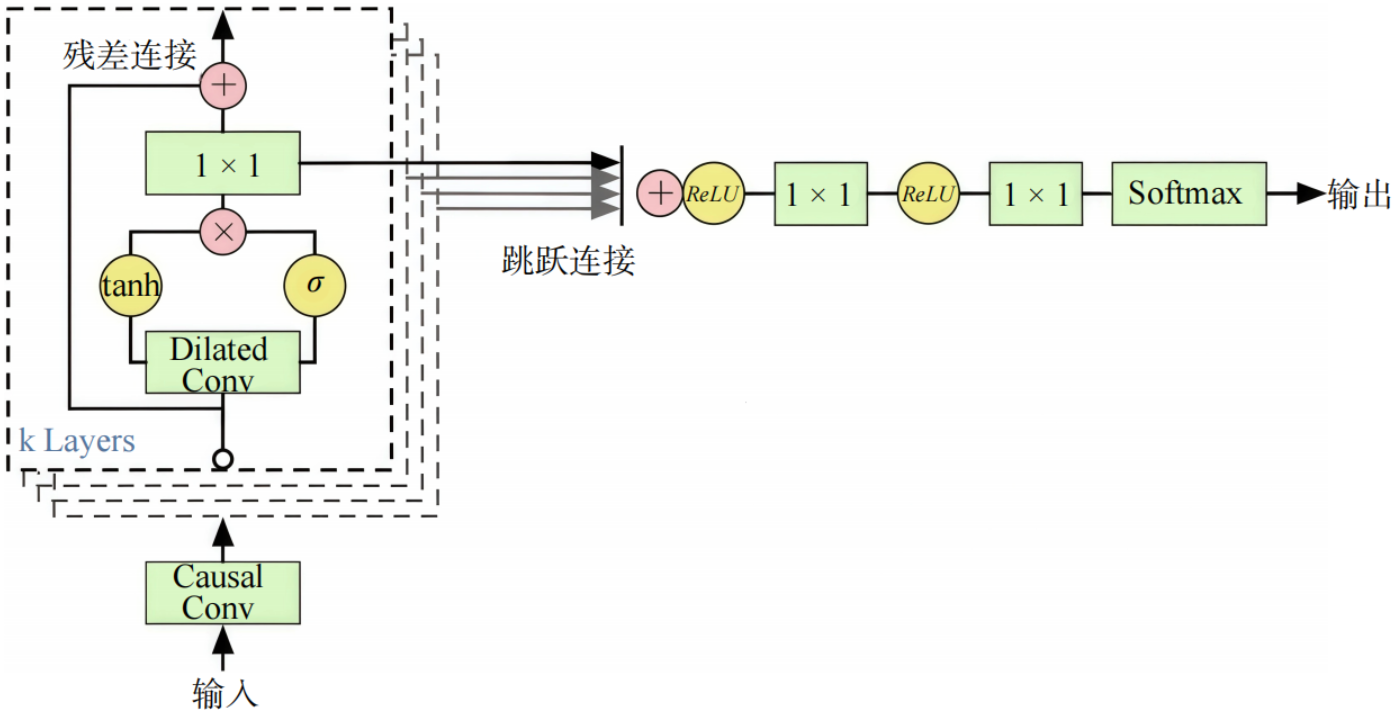
图4 WaveNet结构示意
2.2 AI+声源定位
人类仅用单耳就可实现声源定位,源于不同方向入射的声源受头部、躯干及耳廓等的散射与滤波效应差异;受此仿生启发,有研究人员将单个传声器嵌入预设计的三维超材料结构中,实现了多声源实时定位和分离。现有的绝大多数声源定位系统均通过多传感器拾取信号,并利用时延等特征估计声源位置。
1916年,法国科学家Paul Langevin发明了首台实用化声呐定位系统,可同步测定目标方位与距离。1794年,意大利科学家Lazzaro Spallanzani研究了蝙蝠进行空间定位的基本机制,证实其不依赖视觉导航。1913年,Richardson基于超声波原理发明了回声定位器,奠定了主动式超声定位基础。20世纪10年代,空气声学定位方法兴起。尽管早年的声源定位系统大多源于军事用途,但如今已广泛应用于海洋通信导航、医学诊断、消费电子等民用领域。
2.2.1 传统声源定位方法
传统声源定位方法包括可控波束响应(SRP)、基于高分辨率谱估计和基于时间差(TDOA)等方法。
可控波束响应的典型方法为延迟相加波束形成(DSB),这类方法通常需要预先计算某一方向声源的每个频带两两传感器之间的传播时延,补偿传播时延后求和所有频带所有两两传感器之间的互功率谱;再搜寻全空间所有方向的最大值以定位声源方位。由于可控波束相应方法需要在全空间进行波束扫描,并搜寻最大值,因此该类方法运算复杂度较高。
基于高分辨率谱估计的定位方法,包括最小方差( MV)谱估计和基于特征值分析的方法如MUSIC、ESPRIT以及MODE等算法。这类方法通常需要首先估计空间相关矩阵,且假定声源具备统计平稳,当声源位置移动或者声源二阶统计特性不平稳如语音信号,这类算法的定位性能会呈现不同程度的退化。相比于可控波束响应方法,基于高分辨率谱估计的定位方法每次迭代所需要的运算复杂度更低。
基于TDOA的定位方法有2个阶段:第一阶段估计任意2个传感器接收信号的相对时延,第二阶段根据传感器的相对位置以及第一阶段估计得到的相对时延通过解一组非线性方程得到声源位置的极大似然估计值。这类方法的性能取决于第一阶段估计的相对时延的准确性,Knapp等提出的广义互相关(GCC)方法是应用最为广泛的相对时延估计方法。已有研究结果表明,基于时间差的定位方法在多声源、强噪声或者中等混响以上声学场景性能不佳。
2.2.2 AI声源定位方法
Grumiaux等对基于深度学习的室内声源定位进行了全面的总结,涵盖神经网络架构、输入特征与输出目标、训练及测试数据生成与获取途径,以及深度学习方法。
如图5所示,基于AI的声源定位方法的处理流程与传统TDOA定位方法类似,可分为2个阶段:第一阶段提取定位所需特征,第二阶段通过预训练模型映射输出声源位置。Krause等对比了不同输入特征的声事件检测与定位性能。第二阶段通常采用主流的MLP、CNN、Transformer等网络结构或其组合形式以实现更高的定位精度。
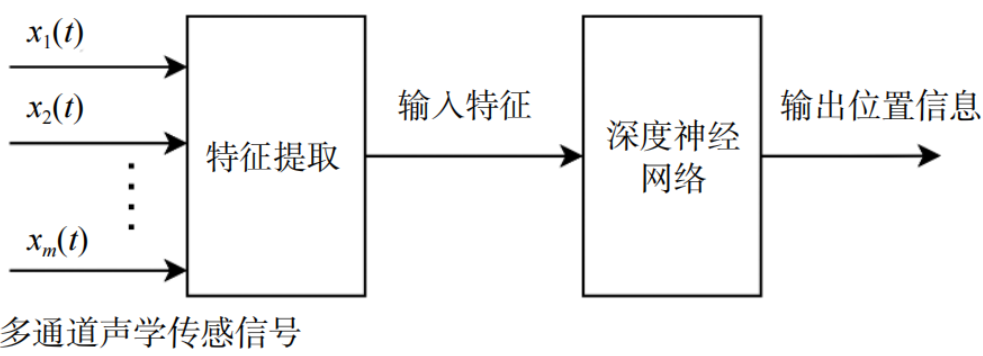
图5 AI声源定位处理流程
AI声源定位方法的位置信息输出常采用分类或回归的方式:前者需将整个位置区域划分为多个子区域,通过神经网络输出各子区域的声源存在概率;后者则通过神经网络直接输出声源坐标信息。相较于分类方法给出的定位是离散值,回归方法给出的定位是连续值,因此其定位精度更高。由于在基于AI的声源定位中,输入特征与输出位置信息维度通常较低,神经网络架构相对简单,因而运算复杂度通常较低。
AI声源定位方法通常需要大量训练数据优化模型参数,常用数据获取方式包括真实实验录制、仿真生成与数据增广3类。录制真实场景典型实验数据的工作量极大。通过仿真生成训练数据是一种比较低成本的方案。研究表明,仅依赖仿真数据训练的模型在真实声学场景下存在鲁棒性不足的问题,而完全采用真实实验数据成本高昂,因此通过数据增广扩充有限真实数据成为折衷方案。
在学习方法方面,当前AI声源定位模型训练以有监督学习为主。目前,基于AI的声源定位已应用于水下目标定位、空中目标定位及超声病灶定位等领域,在诸多场景中展现出优于传统方法的性能,因而具备潜在的研究价值与工程应用价值。
2.3 AI+空间音频
空间音频(spatial audio)旨在通过电声和信号处理手段,实现声场空间信息的捡拾、处理和重放,为听者提供身临其境的沉浸式听觉体验。作为声学、听觉心理和信息处理的交叉领域,空间音频技术已广泛应用于科学研究、消费电子、虚拟/增强现实等场景。Cobos等讨论了AI技术在空间音频领域多个任务中的应用现状。
空间音频核心流程包括信号捡拾(合成)、处理和重放3个主要环节。目前,AI技术主要应用于空间音频的信号处理环节,下面阐述相关的应用现状,重点放在取得了一定进展的方向,简要技术流程图如图6所示。
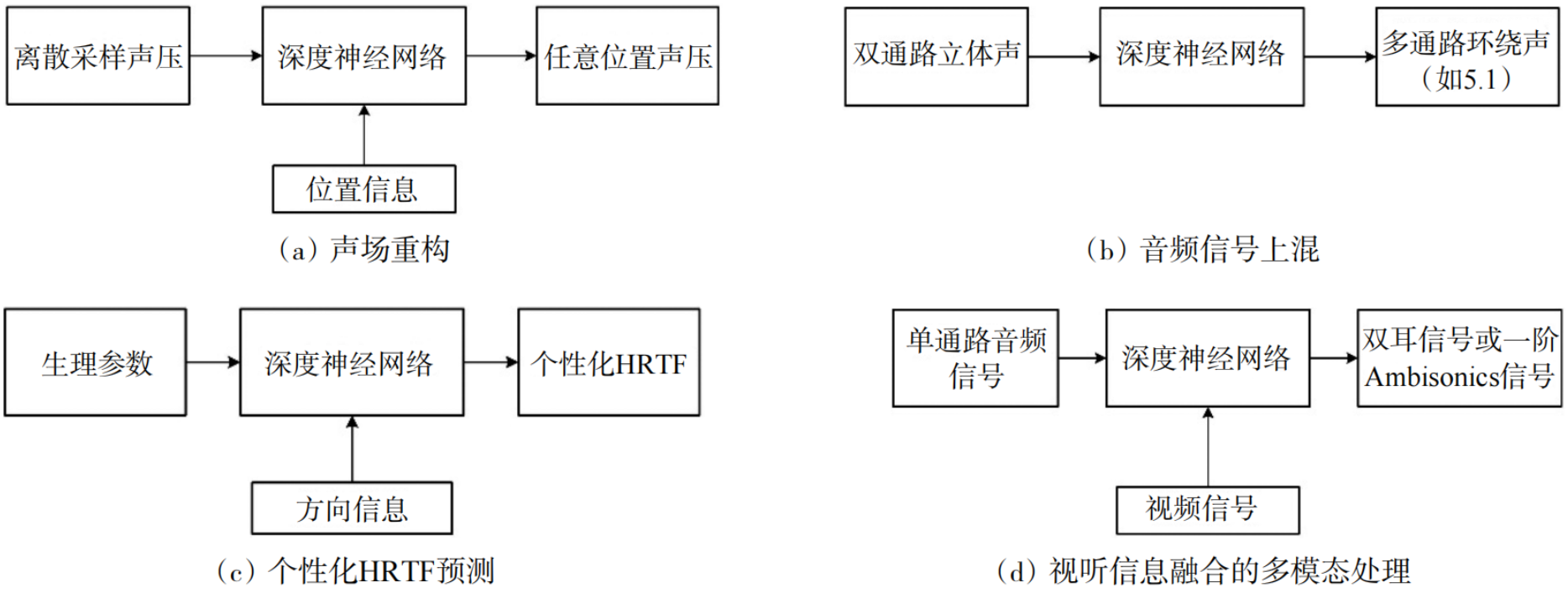
图6 空间音频不同任务的AI应用技术流程示意
2.3.1 声场重构
传声器采集的声场信号是空间离散的,而许多应用场合如声场空间信息分析、6自由度声重放等需重构任意连续位置的声场信号。传统的声场重构方法依赖线性内插或外插,其重构性能在采样密度较低时会显著下降。深度学习的引入为该问题提供了高效解决方案。得益于神经网络对声场共性统计特性强大的学习能力,在稀疏采样下,AI方法的重构精度已逐步超越传统方法。
2.3.2 音频信号上混
空间音频信号上混(upmixing)是将通路数较少的音频信号(通常为双通路立体声)转换为通路数更多的音频格式(如 5.1 通路环绕声)的过程,其技术本质在于拓展原音频信号的空间信息。鉴于AI在声源识别与分离任务中的优势,相关技术被逐步应用于上混领域:Park等采用DNN,以信号子带对数谱为输入,训练中央与环绕通路模型,实现立体声到5.1通路的转换;Choi等设计双DNN架构,分别负责信号分离与渲染,并将包含空间信息的通路ILD特征融入损失函数,强化网络空间信息提取能力。实验结果表明,AI方法在主客观评价中均表现出较传统方法更优的性能,且该优势可能源于更强的方向性与环境氛围分离能力。
2.3.3 个性化头相关函数预测
HRTF是空间音频耳机重放的核心数据,具有显著个体差异性。个性化HRTF的测量需特定设备与场地,过程耗时费力。鉴于HRTF与人体生理参数(人头尺寸、耳廓外形等)高度相关,基于生理参数的个性化HRTF预测成为简便方案。为提升性能,相关研究利用AI技术来实现基于生理参数的个性化HRTF预测。Lee等提出一种MLP−CNN混合模型,利用CNN从耳部图像中提取耳廓生理参数,然后利用MLP预测个性化的头相关脉冲相应( HRIR)。Yao等提出一种基于变分自动编码器(VAE)的方法,并用于实现利用生理参数对HRTF的个性化预测。上述研究结果表明,借助DNN的非线性建模能力,基于AI的HRTF方法普遍取得了较传统线性映射更优异的性能。
2.3.4 视听信息融合的多模态处理
多模态AI技术通过融合视频信息补充缺失的空间维度,实现单通路音频到空间音频的生成。Gao等采用U−Net网络,从视频及对应单通路音频中生成双耳音频信号;Morgado等则利用360°全景视频与自监督学习,通过生成时频掩码分离单通路信号中的方向性分量,进而将其编码为一阶Ambisonics信号。迄今为止,AI已在空间音频的多个任务中得到应用,并在特定场景下展现出优于传统方法的性能,凸显了其在空间音频领域的应用潜力。
2.4 AI+声学环境声检测、分类与噪声智能监测
声学环境声检测分类与监测以声学信号为核心研究对象,旨在通过技术手段实现对复杂声学环境的精准感知与解读。作为声学、心理听觉与AI的交叉融合产物,该技术已广泛应用于智能安防、生态环境治理、智能家居、城市精细化管理等多个领域,成为支撑多场景智能化升级的关键基础技术,尤其在环境噪声污染防治等实际场景中发挥着不可替代的作用。
2.4.1 传统机器学习方法
早期声学环境声检测、分类及监测工作,依赖人工设计声学特征与浅层机器学习分类器,这类方法面对复杂混合声学环境(例如城市中多源叠加噪声、相似声事件干扰)时,存在特征适应性差、抗干扰能力弱、泛化性能不足等局限,难以满足精准化、智能化的应用诉求。
2.4.2 深度学习方法
AI技术为声学环境声检测与分类带来了系统性革新,推动声学环境声检测、分类与噪声智能检测从“人工驱动”向“数据驱动”转型,基于DL的端到端技术路径逐渐成为主流。其核心优势体现在3方面:
一是特征提取的自动化;
二是复杂环境的适配性;
三是推动监测模式的智能化升级,实现噪声源实时定位、等效声级动态计算,改变传统监测依赖人工分析、效率低下的局面。
2016年,IEEE SPS发起的首次国际声学场景和事件检测及分类挑战赛(DCASE)挑战赛,成为该领域标准化与规模化发展的重要里程碑,推动了声学环境声检测与分类及噪声监测技术的快速迭代。
环境声的多样性、复杂性,以及高质量标注数据集的稀缺性,导致模型泛化能力面临挑战。预训练与迁移学习技术的应用有效缓解了这一问题。2017年,Google公司推出AudioSet数据集,为模型的预训练提供了海量数据支撑。基于此,Kong等提出预训练音频模型PANN,如图7所示,其基于AudioSet预训练,可灵活迁移至其他6种音频任务,并在声事件分类上取得当时最好的性能。
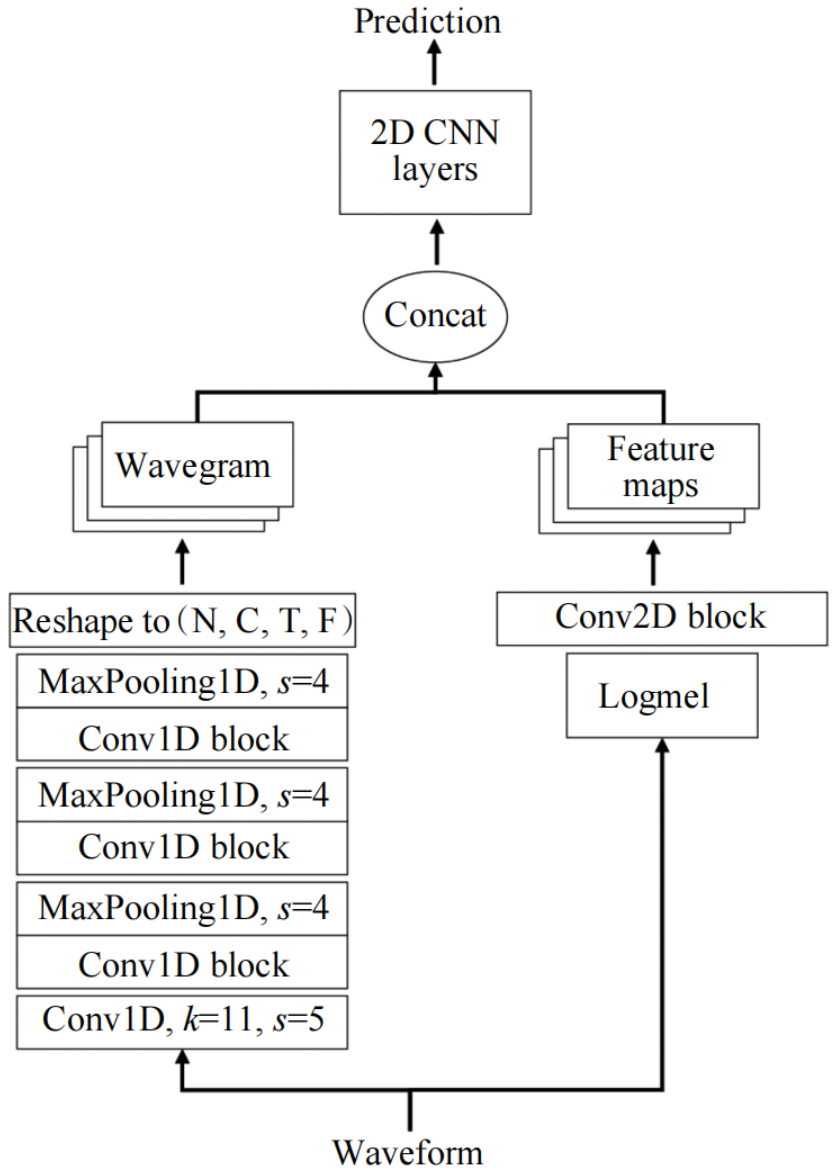
图7 PANN采用的预训练模型结构示意
此外,针对实际场景中噪声、小众声事件等标注稀缺问题,无监督、半监督及自监督学习方法陆续涌现,这类方法通过大量无标签声学数据中的潜在规律,有效扩展了技术在数据缺乏场景中的应用边界。
2.5 AI+声学仿真优化
声学仿真与结构优化是声学工程中的关键任务之一,广泛应用于建筑声学、交通降噪、听觉增强设备以及新型声学材料的研发。随着问题复杂度的增加,如结构多样性提升、优化目标增多、设计空间高维化,传统方法逐渐暴露出不足。AI技术的兴起为这一需求提供了一种可行路径,尤其在数据量不断积累、计算资源持续提升的背景下,AI正逐步成为声学结构优化的重要引擎。
声学仿真通常涉及从结构参数到性能指标的映射,即正向问题(forward problem),而实际工程往往需要解决逆向问题(inverse problem),即从目标性能出发反推结构设计。随着DL和强化学习(RL)的兴起,研究者开始借助AI技术在复杂系统中实现反向设计、高维参数映射以及快速性能预测。
2.5.1 传统声学仿真与优化方法
有限元法是声学结构分析中应用最广泛的数值技术,能够求解复杂边界条件下的声场分布。然而其缺点也非常突出:每次更改结构参数都需重新建模和求解,导致大量冗余计算。拓扑优化是一种数学驱动的结构形貌优化方法,常用于最大化某一目标(如吸收系数、阻抗匹配等)。然而,这类方法往往依赖梯度信息,难以适应非线性材料行为,且不易扩展至多目标情形。为提升优化效率,部分研究结合了遗传算法、粒子群算法等启发式搜索方法,缓解了参数空间维度高带来的问题。但这些算法本质仍是黑盒搜索,计算效率低、收敛性差,且在复杂结构多目标优化中仍需大量仿真样本支持。
2.5.2 AI声学仿真优化
AI反向优化的基本思想是利用神经网络拟合性能与结构参数之间的映射关系。Donda等指出MLP适用于低维连续参数预测,而CNN适合处理网格结构的拓扑优化问题,在预测声学带隙、吸声频率等方面效果显著。近年来兴起的PINN备受关注。该类模型将物理定律(如声波传播方程)嵌入损失函数中,使训练过程兼具数据驱动与物理约束,提高了泛化能力与物理一致性。
在具体应用场景中,AI技术已深度融入周期性声子晶体、声学超材料等领域。Shi等采用LSTM−Transformer串联的类自编码器模型,如图8所示,实现了空间折叠声学超材料(SFAM)的中低频宽带隔声反设计与空间优化,为空间受限场景下的声学超材料高效设计提供了可行方案,其预测性能如图9所示。Zea等借鉴ResNet架构,实现宽频率范围、不同尺寸与流阻率的矩形吸声材料在强边缘衍射场景下的吸声系数的精准估计,且在400 Hz以下低频段及小尺寸吸声材料上的性能显著优于传统双麦传声器。随着AI与物理建模的融合深化,越来越多研究开始探索多物理场(如声−热、电−声)的耦合优化。未来,基于小样本学习、自监督预训练与迁移学习的算法将进一步降低对大量仿真数据的依赖。
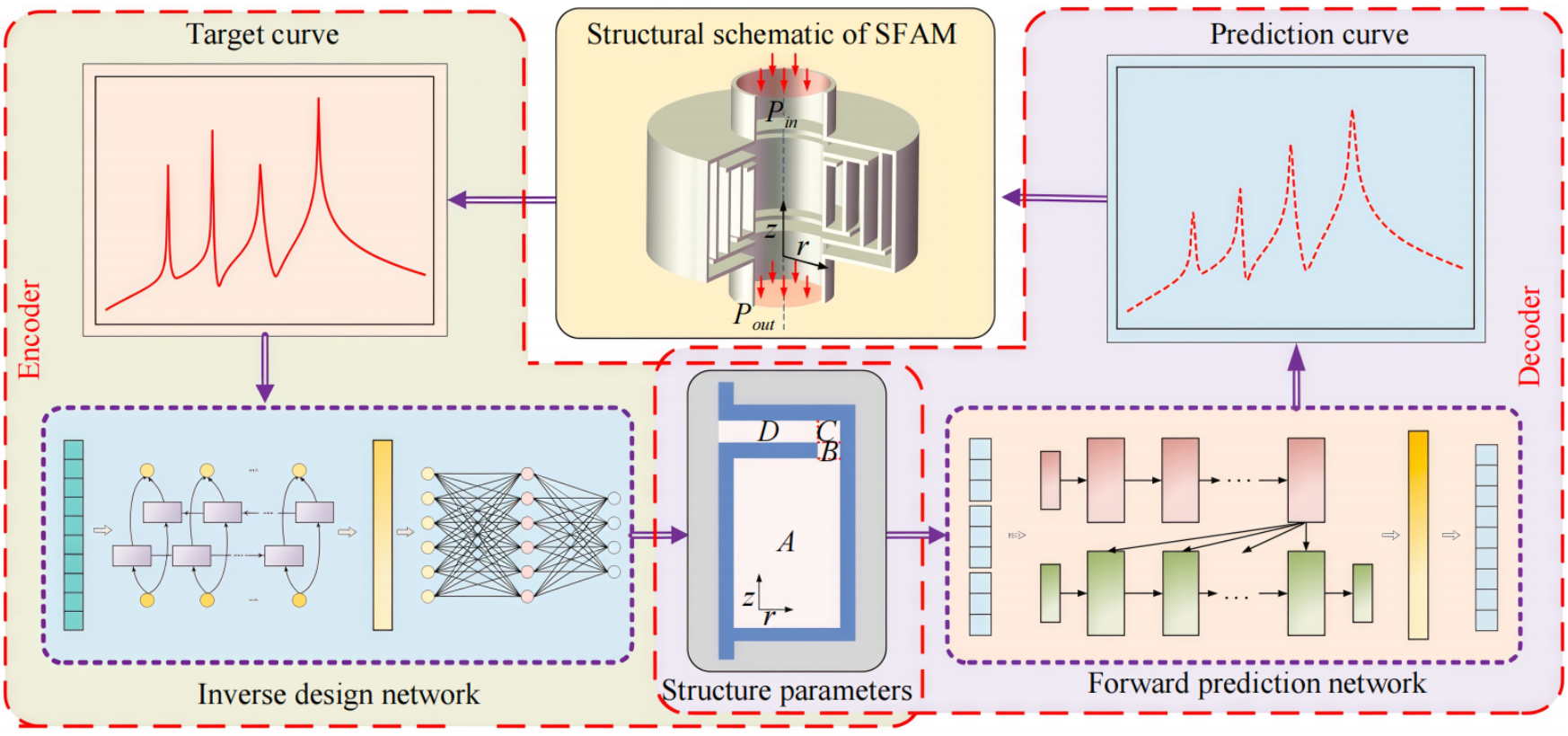
图8 用于隔声材料设计的网络结构示意
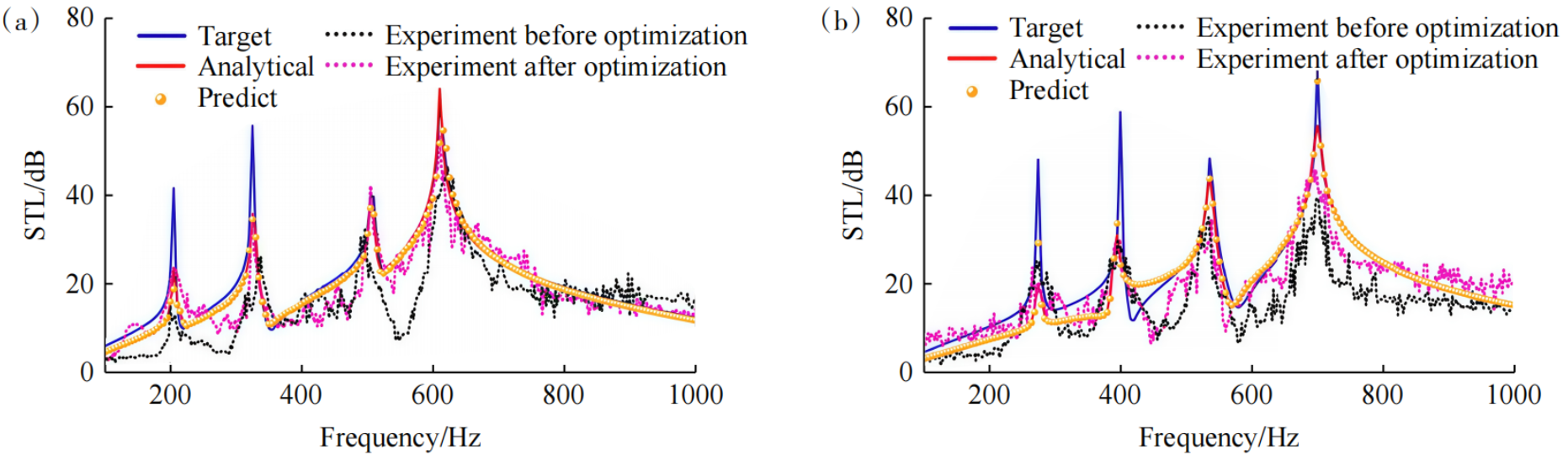
图9 经过AI模型优化前后隔声量结果对比
3、面临挑战
3.1 泛化性问题
泛化性是制约AI在声学领域落地的核心瓶颈,其本质是模型对“未见场景”的适配能力不足。Rohlfs等将泛化分为样本泛化、分布泛化、域泛化、任务泛化、跨模态泛化及范围泛化6类。
3.2 数据依赖与质量问题
数据是AI技术的燃料和基础,其依赖与质量问题直接制约模型的性能上限。对于声学模型而言,数据相关难题主要集中在2个方面:
一是高质量标注数据的获取瓶颈;
二是数据质量的固有缺陷。
近年来,大模型的出现进一步加剧了该挑战,其对数据规模的需求呈指数级增长,需以数十万乃至亿小时级的海量音频数据为支撑,远超传统模型的数万至百万级需求,使得数据缺口被进一步放大。此外,数据依赖问题还延伸至合规性和安全层面。
3.3 复杂度问题
AI模型的复杂度与声学应用场景的资源约束间存在突出矛盾。从模型层面看,现有通用AI模型的参数规模已达千亿级至万亿级,运算复杂度往往随参数规模非线性增长,导致云端部署的算力与能源成本居高不下。从应用场景看,声学技术的落地场景日益多元,对模型提出了严苛的要求,现有解决方案可分为3类:
一是模型压缩技术,知识蒸馏(knowledge distillation)通过“教师−学生”架构实现性能迁移;
二是模型架构,如结合声学先验设计轻量级网络架构;
三是硬件协同,存算一体芯片通过集成存储与运算单元,降低数据搬运带来的功耗与延时,为低功耗场景提供硬件支撑。
这些技术的核心是在模型性能与复杂度之间寻求最优平衡,但在极端低资源场景下的性能损失控制仍需进一步研究。
3.4 实时性问题
实时性是AI声学技术面向实际应用的关键指标,其需求差异源于声学信号的传播特性与应用场景的功能定位。从时延要求看,不同场景的阈值跨度极大。实时性的核心瓶颈包括2方面:一是算法复杂度,二是算法延迟。因而解决方案需针对性优化:针对复杂度问题,可采用轻量化模型设计、模型压缩等技术降低运算量;针对延迟问题,可选择时域处理方法或在时频域中采用短帧移与重叠保持法(OLS)。值得注意的是,实时性往往与性能存在平衡,如何在极端时延约束下保证处理效果,是当前研究的重点方向。
3.5 多模态融合问题
多模态融合已成为提升声学技术性能的重要路径,但在声学领域的应用仍面临3类核心挑战。其一,模态异构性;其二,融合效率与性能的平衡;其三,低资源场景的多模态数据稀疏。当前研究主要聚焦跨模态精准对齐、轻量化融合架构和低资源适配技术,未来需进一步结合声学物理规律优化,推动跨模态技术实用化。
4、结论与展望
AI与声学的深度融合,推动了声学从基础研究到工程应用的全面革新。
在语音信号处理领域,AI已实现从特征工程到端到端建模的范式转变。其中,基于深度学习的语音识别、增强和合成技术,不仅在特定任务中超越了人类水平,还通过多模态融合和生成式模型拓展了应用边界。然而,这些技术在实际部署中仍受限于数据依赖性和计算资源需求。
AI在声学中的应用将呈现以下发展趋势:首先,跨模态与多任务协同将成为技术突破的关键方向。其次,小样本与自监督技术将缓解强数据依赖问题。未来,基于自监督学习和元学习的框架可以广泛应用于声学任务中,通过挖掘数据内在规律和跨领域知识迁移,降低算法对数据的依赖。此外,物理信息引导的生成式模型有望生成更符合真实声学规律的数据,进一步提升模型泛化能力;再者,边缘计算与轻量化部署将推动基于AI的声学技术的普及。
AI在声学中的应用和发展也面临诸多挑战。在基础理论层面,声学与AI的交叉研究尚未建立完善的理论框架,需要重点研究以指导模型的设计和性能评估。在技术层面,如何平衡算法复杂度与性能,实现可扩展性的实时处理,仍是亟待解决的关键技术难题。此外,在伦理与隐私保护方面也需要行业规范和技术防护的双重保障。
未来,随着基础理论的突破、技术的迭代和跨学科合作的深化,“AI+声学”将在海洋探测、医疗诊断、虚拟现实、环境声学等领域进一步发挥重要的作用,以最终实现从实验室研究、单点技术落地到大规模产业化应用的跨越。
本文作者:郑成诗、李安冬、饶丹、袁旻忞、江峰、李晓东
作者简介:郑成诗,中国科学院声学研究所,噪声与音频声学实验室,中国科学院大学,研究员,研究方向为通信声学。
文章来源:郑成诗, 李安冬, 饶丹, 等. 人工智能在声学中的应用及展望[J]. 科技导报, 2026, 44(4): 62−78.





 下载app
下载app