问题分诊室
谷歌最新成果:低像素→高像素图片合成的新高度
发布时间: 2021-09-08
原文标题:High Fidelity Image Generation Using Diffusion Models
作者:GoogleAI
译者:刘媛媛
自然图像合成是一类机器学习(ML)任务,其具有广泛应用及许多设计挑战。图像合成任务的一个例子是图像超分辨率,其训练模型将低分辨率图像转换为高分辨率图像(例如:RAISR)。

超分辨率有许多应用,从恢复旧的全家福照片到改进医学图像成像系统。另一个图像合成任务是类条件图像生成,其训练模型将输入类标签生成样本图像。生成的样本图像可用于提高下游模型的图像分类、分割等性能。
通常,这些图像合成任务由深度生成模型执行,例如 GAN、VAE 和自回归模型。然而,当在困难的高分辨率数据集上经过训练合成高质量样本时,这些生成模型中的每一个都有其缺点。例如,GAN 经常受训练不稳定和模式崩溃的影响,而自回归模型通常会受到合成速度缓慢的影响。
最初于 2015 年提出的扩散模型由于其训练稳定性及在图像和音频生成方面可观的样本结果质量,最近引起了人们的广泛关注。
与其他类型的深度生成模型相比,扩散模型提供了潜在的有利权衡。它通过逐渐添加高斯噪声来损坏训练数据,慢慢消除数据中的细节直到它变成纯噪声;然后训练神经网络来扭转这种损坏过程,运行这个反向损坏过程通过逐渐去噪直到产生干净的样本来合成来自纯噪声的数据。这个合成过程可以解释为一种优化算法,它遵循数据密度的梯度来产生可能的样本。
如今,谷歌团队提出了两种相互关联的方法,它们突破了扩散模型的图像合成质量的界限——一种通过重复细化(SR3)的超分辨率和一种称为级联扩散模型(CDM)的类条件合成模型。
通过扩大扩散模型和精心设计的数据增强技术,可以胜过现有的方法。
具体来说,SR3 在人类评估中获得了超过 GAN 的强大图像超分辨率结果。CDM 生成的高保真 ImageNet 样本在 FID 分数和分类准确度分数上均大大超过 BigGAN-deep 和 VQ-VAE2。
SR3:图像超分辨率
SR3 是一种超分辨率扩散模型,它以低分辨率图像作为输入,从纯噪声中构建相应的高分辨率图像。该模型在图像损坏过程中进行训练,其中噪声逐渐添加到高分辨率图像中,直到只剩下纯噪声为止。然后它学习逆转这个过程,从纯噪声开始,并通过输入低分辨率图像的引导,逐步去除噪声以达到目标分布。
通过大规模训练,当缩放到输入低分辨率图像的 4 倍到 8 倍的分辨率时,SR3 在人脸和自然图像的超分辨率任务上取得了强大的基准测试结果。这些超分辨率模型可以进一步级联在一起以增加有效的超分辨率比例因子,例如,将 64x64 → 256x256 和 256x256→ 1024x1024 的人脸超分辨率模型堆叠在一起,以执行 64x64 → 1024x1024 的超分辨率任务。
谷歌团队使用人类评估研究将 SR3 与现有方法进行比较。
他们进行了一项两种可选的强制选择实验,要求受试者被问及“你猜哪个图像来自相机?”时,在参考的高分辨率图像和 SR3 模型输出的高分辨率图像之间进行选择,谷歌团队通过混淆率来衡量模型的性能(评估者选择模型输出的图像与参考图像的时间百分比,其中完美的算法将实现 50% 的混淆率)。这项研究的结果如下图所示。
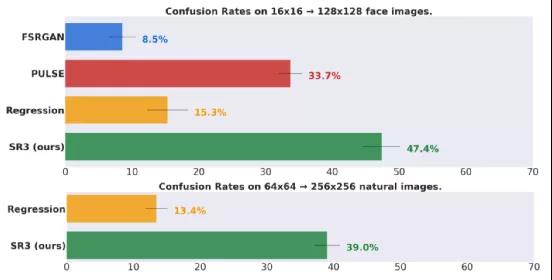
图 1:上图:在16x16 → 128x128 人脸图像上实现了接近 50% 的混淆率,优于最先进的人脸超分辨率方法 PULSE 和 FSRGAN。下图:在 64x64 → 256x256 自然图像这一更困难的任务上实现了 40% 的混淆率,大大优于回归基线。
CDM:类条件 ImageNet 生成
在展示了 SR3 在执行自然图像超分辨率方面的有效性之后,谷歌团队更进一步,将这些 SR3 模型用于类条件图像生成。
CDM 是在 ImageNet 数据上训练以生成高分辨率自然图像的类条件扩散模型。由于ImageNet 是一个困难的高熵数据集,谷歌团队将 CDM 构建为多个扩散模型的级联。
这种级联方法涉及将多个空间分辨率的多个生成模型链接在一起:首先是一个以低分辨率生成数据的扩散模型,然后是一系列 SR3 超分辨率扩散模型,逐渐将生成的图像的分辨率提高到最高分辨率。众所周知,级联提高了高分辨率数据的质量和训练速度,这可以在先前的研究(例如:自回归模型和 VQ-VAE-2 )和扩散模型的并发工作得以证明。正如谷歌团队下面的定量结果所证明的那样,CDM 进一步突出了扩散模型中级联对样本的质量和下游任务的作用(例如:图像分类)的有效性。
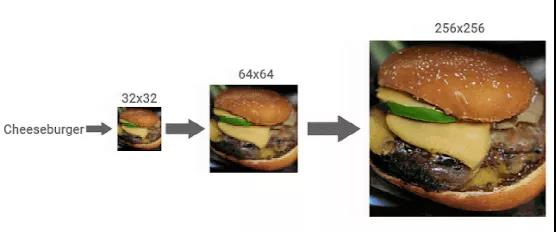
图 2:包含一系列扩散模型的级联通道示例:首先生成低分辨率图像,然后执行上采样得到最终高分辨率图像。这里的通道用于类条件 ImageNet 生成,它从 32x32 分辨率的类条件扩散模型开始,然后是使用 SR3 的 2x 和 4x 类条件超分辨率。

图 3:256x256 级联类条件 ImageNet 模型中生成的部分图像
除了在级联通道中包含 SR3 模型外,谷歌团队还引入了一种新的数据增强技术,称为条件增强技术,它进一步提高了 CDM 的样本结果质量。
CDM 中的超分辨率模型是在数据集的原始图像上训练的,在生成过程中需要对低分辨率基础模型生成的图像执行超分辨率处理,但与原始图像相比,低分辨率的基础模型生成的图像质量可能还不够高。这导致超分辨率模型的训练测试不匹配。条件增强是指将数据增强应用于级联通道中每个超分辨率模型的低分辨率输入图像。这些增强(在谷歌团队的案例中包括高斯噪声和高斯模糊)可防止每个超分辨率模型过度拟合其较低分辨率的调节输入,最终为 CDM 带来更好的高分辨率样本质量。
总之,类条件 ImageNet 生成模型中,CDM 生成的高保真样本在FID 分数和分类准确度分数方面均优于 BigGAN-deep 和 VQ-VAE-2。CDM 是一种纯生成模型,与 ADM 和 VQ-VAE-2 等其他模型不同,它不使用分类器来提高样本质量。有关样品质量的定量结果,请参见下文。
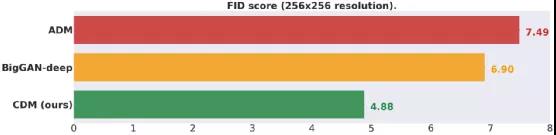
图 4 对于不使用额外分类器来提高样本质量的方法,类条件 ImageNet 生成模型在 256x256 分辨率下的 FID 得分(越低越好)
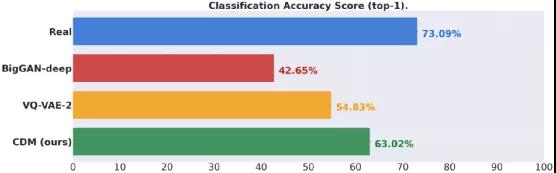
图5 ImageNet 在 256x256 分辨率下的分类准确度得分,衡量在生成的数据上训练的分类器的验证集准确度(越高越好)。CDM 生成的数据比现有方法获得了更显着的效果,缩小了真实数据和生成数据之间在分类精度上的差距。
总而言之,借助 SR3 和 CDM,谷歌团队将扩散模型的性能提升到超分辨率和类条件 ImageNet 生成基准的最新技术水平。关于谷歌团队这些进展的更多信息,可阅读论文ImageSuper-Resolution via Iterative Refinement、Cascaded DiffusionModels for High Fidelity Image Generation
Refrence:
https://ai.googleblog.com/2021/07/high-fidelity-image-generation-using.html?m=1





 下载app
下载app