导语:什么使一个解释具有足够说服力?来自圣塔菲研究所外聘学者、卡耐基·梅隆大学社会与决策科学系教授 DeDeo 和 Zachary Wojtowicz 最近在《认知科学趋势》杂志上发表的一篇论文,使用贝叶斯定律,证明为什么人们会倾向于接受对他们而言特定的解释;同时阐述了在科学或道德问题上,一个优秀的解释所应当具有的特征。我们可以经由该框架,重新解释推动诸如阴谋论、妄想、乃至极端主义意识形态等现象出现的原因。
作者:郭瑞东
审校:赵雨亭
编辑:邓一雪

论文题目:
From Probability to Consilience: How Explanatory Values Implement Bayesian Reasoning
论文地址:
https://secure.jbs.elsevierhealth.com/action/cookieAbsent?code=null
1. 解释的四个维度
本文作者 Simon DeDeo 专注于研究人类如何使用语言及观念作为信号,以此来构建外部世界。他指出:“对于现有最激烈和最具争议性的话题,我们经常在结论上达成一致。但对解释存在分歧。”对怎么才算是有说服力的解释,不同的人会给出不同的答案——共识并不存在。而该论文在认知科学领域的研究揭示了一个解释具有的多样性价值观或维度。
认知的概率模型表明,人们根据事情发生的可能性来评估哪些概念是真实的解释。贝叶斯认知模型进一步假设个人将这个评价分为两部分:(i)证据使解释变的可能的程度——它衡量一个解释在观察到的证据下的可能性;以及(ii)观测前解释的可能性,代表在看到证据之前,人们倾向于相信该解释的程度。
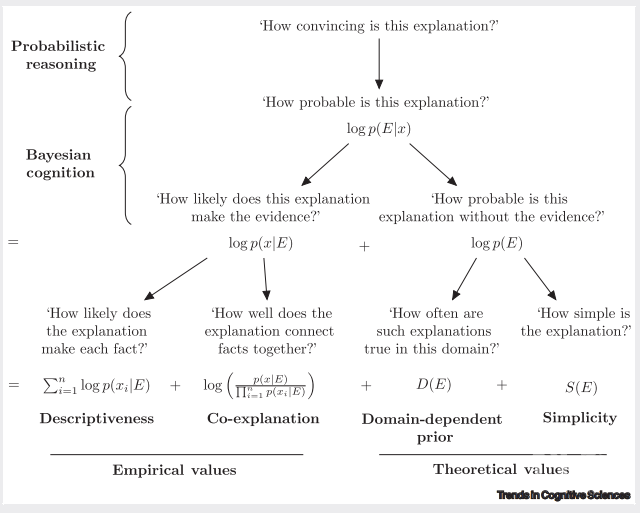
图1. 解释的四个评价维度:某一解释可否合理地使每个待解释的事实更有可能发生(即可描述性);某一解释能否将不同的事实整合起来(通用性);在这一领域,某一解释是否经常是对的(场景无关);这一解释是否足够简单(简洁)
前两个评价标准,是实用指标——如果一个解释对事件的描述与真实情况差距过大,或者这个解释仅仅是一个恰好这样的巧合,那么人们倾向于不相信这样的解释。例如,家长质问孩子为何考试成绩不及格,孩子或许回答堵车迟到,抑或是只答完一半试卷。但我们可以轻而易举发现,即使只计算答题的半张卷子,平均起来也还是不及格——此时,孩子解释就是可描述性不足。而若孩子回答由于天热头痛的同时,同期进行的另一门考试则成绩优异,这就展示了天气这个解释缺少通用性。
2. 解释的简洁性
上述框架中的后两个指标,与解释对应的事实无关——其代表任何一个解释在特定的背景知识下自身的价值。在贝叶斯框架中,这种知识需要拥有在特定领域内精确校准的先验作为现实世界能力的一部分。例如,一个优秀的汽车修理工可以通过借鉴他们在类似汽车上的经验,预见到发动机故障最可能的解释。任何解释都不能忽视先验概率。对患者的诊断,则需要考虑该性别及年龄段的人群罹患对不同疾病的基础概率作为先验知识。
简单是一个好的解释的特征之一。在科学领域,这被称为奥卡姆剃刀原则,例如:“我能编写的产生这些结果的最短程序是什么。”其他人则更喜欢 Wojtowicz 和 DeDeo 所说的“联合解释”——这种解释看起来是用一个答案解决多个难题,之后根据新的发现来评估结果。在物理学中,这通常表现为通过看似不同的模式寻找一个统一的原理或机制。而根据 Akaike Information Criterion 所言,在解释中增加一个参数(提高模型的自由度),需要在加入该参数之后——相比于旧解释——新解释让待解释事件发生的概率提升2.7倍,该参数才可被视为合理的。
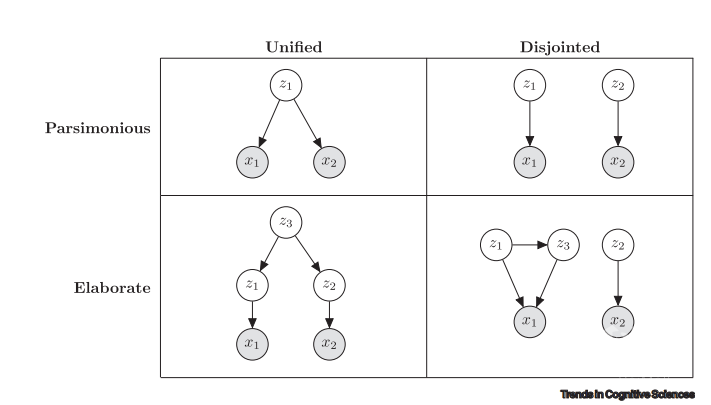
图2. 评估不同因果解释简洁性
上图中阴影节点表示其他节点表示假定的潜在原因,而箭头表示因果关系。评估简单性是计算一个解释所调用的参数数量的潜在标准。评估简单性的第二种方法是统一性,它为衡量一个理论提供了一场包罗万象理论汇总的程度,对世界多种特征的解释可以独立地沿着每一个维度变化,因此,该解释的整体简单性可以被认为是两者的加权组合。
但是,最迷人的简单解释可能与更全面地解释世界的复杂解释相冲突。部分挑战在于解释和预测是不一样的:深度学习算法可能以不可思议的准确性预测不久的将来,但却无法解释他们为此而建立的模型。“万有理论”则可能无法预测训练数据集之外的世界。
3. 从多个维度评价对同一事实的多种解释
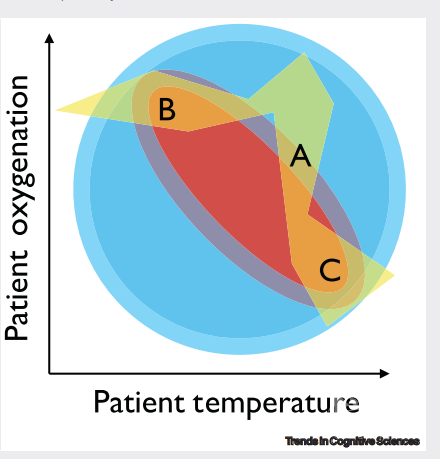
图3. 一个常见的区分解释性价值的范式-疾病诊断
上图说明了这项任务的一般情况,其中有三种可能的解释(红色、蓝色和黄色表示阴影,每种颜色的密度表示概率),对应不同的症状模式。
在我们的框架中,蓝色的解释在可描述性上(它允许更广泛的结果)与共同解释力上表现更差。红色的解释具有更好的描述性(更窄的范围为可能性)与共同解释力(病人体温高通常伴随着低血氧)。黄色的解释与红色的相似之处在于,它同样有描述性又能解释所有现象,但相比之下,它就没有呈现出体温和血氧间的简单关系。
面对三个不同的患者(a、b 和 c) ,这些解释有不同的价值——红色的解释比黄色的解释描述性低(患者 a 有点超出红色的正常范围) ,但有比蓝色更高的共同解释(通过三个患者的体温预测他们的血氧水平)。对于患者 a 的特殊情况,黄色也比红色有更好的共同解释性;在黄色的解释下,患者a的血氧水平处于红色解释允许的范围外,对应着更可预测的体温。
哪种解释相较最好取决于上下文。即使黄色的解释有更好的描述性得分和共同解释力,但一个人可能仍然会更倾向于红色、甚至蓝色的解释。例如,黄色的解释可能会涉及血氧和体温之间的复杂关系——通过引起同时存在两种疾病、或者通过一种复杂的不同潜在条件的相互作用解释这三个病例——因而不够简洁。
解释评估相对于一个(通常稳定)背景本体论:在这里即为血氧和体温。如果本体论发生了变化,值也随之发生了变化。例如,如果医生确定了一个指标,将其称为体温减去“血氧” ,那么红色的解释将变得具有更低共同解释力,并需要更多的解释性描述,同时这些指标的总和保持常数。
4. 好的解释具有复杂性
对因果关系的错误认知将会在日常生活中引起麻烦——阴谋论是一个很好的例子。阴谋论的盛行,说明y一旦对本文所说的“共同解释力”的过度倚重,结果可能会导致认知偏误。以俄克拉荷马城爆炸案制造者 Timothy McVeigh 为例,他在爆炸发生后不久被捕——因为他无照驾驶,且乘客座位上有一把上了膛的枪。人们很难理解为什么一个犯罪策划者会如此粗心大意,有些人更容易相信 McVeigh 是一个精英阴谋的替罪羊。
“阴谋论在很多方面都是很好的解释。” DeDeo 表示。“阴谋论者的错误往往在于审美上的不平衡。” 忽视了某一领域的常识,过分强调与“统一”解释相关的价值观。由于忽视了真正的复杂性,无所不包的答案是有代价的。
阴谋论往往既不正常地解释又不正常地描述事情:它指出,看似真理事实的日常生活,其实是相互关联的隐藏事件。经由操纵事实,阴谋论诱使受试者看到虚幻的相关性。那些倾向于超自然思维的人也更容易受到合取谬误的影响,这可能是由于过分重视共同解释的结果。在相信阴谋论的倾向上,存在着很大的个体差异:那些阴谋论的信众,相信人类更容易相信别人。
DeDeo 表示:“当解释起作用时,它们会使我们着迷。”他引用麦克斯韦电磁学理论作为一个非常有用的总结——解释将两种看不见的力量“统一”起来。但是,当一种审美观占主导地位时,同样的魅力也可能被滥用。
根据 DeDeo 的说法,最终让人保持诚实的是与其他人互动,它们对于如何构成一个令人满意的解释有着不同的方式。
5. 总结:评估模型,不应当只看预测性能
深度学习、复杂系统的自动化建模,本质都是对现实世界的一种建模。而当前评估建模时流行的指标和方法——例如通过交叉验证判定模型的预测精度——都只对应了贝叶斯框架中的某个部分——如描述性或共解释性——而忽略了其它维度。通过了解优秀可服众的解释应当具备的指标,能够让我们建立模型时,从一开始就选择更多样化的策略。同时我们还可以以此来评价模型,从而使得模型能更好地指导生活。
关于何为令人信服的解释,还有很多未知问题——例如关于优秀解释的评价标准,是不是随文化改变的、抑或是人的心智发育有什么关系(这些指标是来自先天赋予还是后天学习)?这四个解释的维度,是如何共同进化的?以及更根本的问题,究竟何为解释?是什么将对事件的解释和描述/观测区分开的?解释中用到的特征,是需要对预测未来更有利,还是需要侧重让普通人理解?这些问题,都需要进一步的探索。
 微信公众号
微信公众号
 下载app
下载app
 京公网安备 11010202008974号
京公网安备 11010202008974号